1.
Difficultés de la RAP.
Le signal de la parole possède des caractéristiques qui compliquent son
interprétation et augmentent le nombre de données à traiter.
Il présente un caractère redondant, c’est à dire qu’il renferme plusieurs
types d’informations : les sons, la syntaxe et la sémantique de la phrase,
l’identité du locuteur et son état émotionnel. Si cette redondance lui confère
une bonne résistance au bruit, elle oblige à extraire du signal les informations
pertinentes, en essayant de ne pas trop les dégrader.
Le signal est très variable selon le locuteur, c’est la variabilité
interlocuteur (timbres différents, différences morphologiques, homme ou femme), mais
également pour un même locuteur. On parle alors de variabilité intralocuteur, due à
l’état émotionnel, la voix chantée, parlée, chuchotée, enrouée. Il
s’ajoute aussi les variabilités dues au milieu (le bruit perturbe la prise de son et
augmente la variabilité intralocuteur) et à l’acquisition du signal.
Le signal est continu, c’est à dire que lorsqu'on écoute parler une personne, on
perçoit une suite de mots, alors que l'analyse du signal
vocal ne permet de déceler aucun séparateur. Le même problème de segmentation se
retrouve à l'intérieur du mot. Celui-ci est perçu comme une suite de sons
élémentaires (les phonéticiens trouveront le même nombre de phonèmes dans une phrase)
que l'analyse ne permet pas d'isoler en segments distincts du signal acoustique. Le signal
de la parole est évolutif et il est généralement admis qu'il est nécessaire de
l'analyser selon une période de 10 ms..
Il y a également le phénomène de coarticulation. C’est l’effet contextuel
que produit un phonème sur ses voisins. Il est provoqué par le fait que, lors de la
prononciation d’un phonème, l’appareil articulatoire se prépare pour la
production du suivant.
Ces caractéristiques compliquent la tâche d’un système de RAP qui doit être
capable de décider " qu’un [a] prononcé par un adulte masculin
est plus proche d’un [a] prononcé par un enfant, dans un mot différent, dans
un environnement différent et avec un autre microphone, que d’un [o]
prononcé dans la même phrase par le même adulte masculin " [MAR 90].
Toutes ces particularités ont modéré l’optimisme des débuts. La réaction, au
commencement des années 60, a été d’introduire des hypothèses simplificatrices.
La première étape a été d’étudier la reconnaissance:
 Retour au début du
document
Retour au début du
document
2.
La reconnaissance monolocuteur.
Pour résoudre le problème qui vient d’être énoncé, il est souvent utilisé
une approche globale, c’est à dire que les mots ne sont pas découpés en entités
plus élémentaires. Cette approche est une manière de contourner les difficultés de
l’analyse linguistique, en insistant sur le Décodage Acoustico-Phonétique
(DAP). Le
DAP peut se définir comme un transcodage de l’onde vocale en unités phonétiques.
L’approche globale peut se décomposer en deux étapes: l’apprentissage et la
reconnaissance [HAT 91].
Durant la phase d’apprentissage, le locuteur prononce un à un tous les mots qui
composent le dictionnaire. Le signal produit est analysé afin de produire une image
acoustique du mot (spectrogramme par
exemple). Cette image constitue, pour un mot donné, la forme de référence qui sera
sauvegardée dans le dictionnaire.
Lors de la phase de reconnaissance, le locuteur ayant réalisé l’apprentissage,
prononce un mot qui sera traité selon la même méthode que lors de l’apprentissage.
L’identification de l’image obtenue se fait par comparaison avec les formes de
références contenues dans le dictionnaire. Celle obtenant la ‘distance’ la
plus courte (tout en étant inférieure à un seuil de rejet), est considérée comme
reconnue. Une technique couramment utilisée pour calculer la distance, ou plutôt la
mesure de dissemblance, entre les formes de tests et de références, est la méthode de comparaison dynamique.
Ce type d’approche est vite limité dés qu’il s’agit d’étendre le
nombre de locuteurs, le vocabulaire ou d’améliorer l’insensibilité à la variabilité. Cela conduit à
multiplier les formes de références; le coût de l’apprentissage, la quantité
d’informations et le temps de calcul deviennent vite importants.
Retour au début du
document
3. La
comparaison dynamique.
Lorsqu’un locuteur, même entraîné, répète plusieurs fois une phrase ou un
mot, il ne peut éviter les variations du rythme de prononciation ou de la vitesse
d’élocution. Ces variations entraînent des transformations non linéaires dans le
temps du signal acoustique. La
non-linéarité vient du fait que les transformations affectent plus les parties stables
du signal que les phases de transitions.
Une méthode pour s’affranchir de ces transformations est de réaliser une
normalisation temporelle [SAK 78] en même
temps que la comparaison des deux mots. On peut utiliser pour cela une technique de
comparaison dynamique, ou alignement temporel dynamique (DTW: Dynamic Time Warping)
introduit en reconnaissance de la parole par Vintsujk [VIN 68].
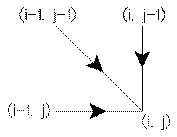
Soit les formes A et B, deux images acoustiques (des spectrogrammes dans le cas de la figure 5), de longueur I et J, à comparer.
L’alignement dynamique entre ces deux formes (figure 5) est représenté par le
chemin {C(k)=(n(k), m(k)); k=1 à K}, avec C(1)=(1, 1) et C(K)=(I, J).
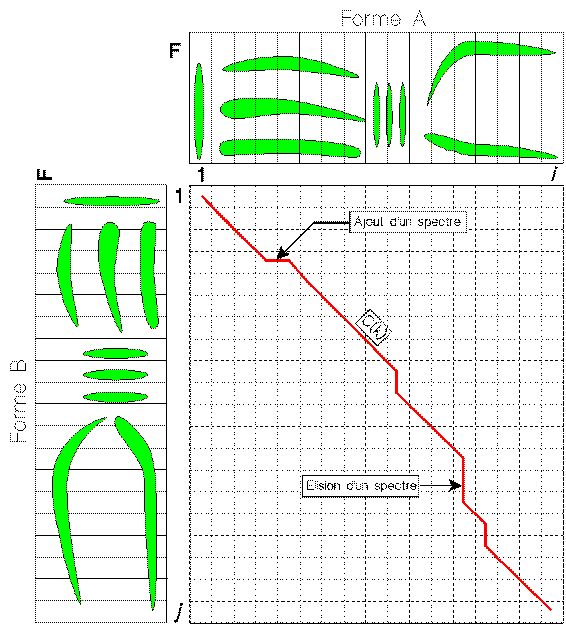
Figure 5:. Alignement temporel dynamique.
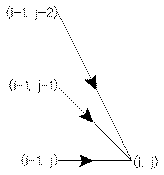
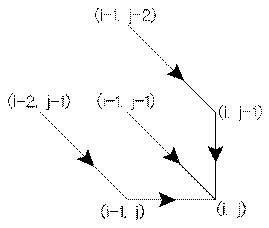
Pour respecter la réalité, il est appliqué des contraintes (figure 6) sur les fonctions n(k) et m(k) afin
qu’elles soient croissantes et respectent des conditions de continuité (exprimées
par les contraintes).
Figure 6. Exemples de contraintes locales.
Pour cela, il faut calculer, sur tout le domaine [I, J], la distance cumulée g(i,j),
avec i Î [1, I] et j Î
[1, J], en tenant compte des seules transitions autorisées par les contraintes
utilisées. Dans le cas de la contrainte de Sakoe-Chiba exprimée par la figure 6a, on aura, (avec d(i,j) la distance entre
les deux ‘tranches’ spectrales A(i) et B(j)):
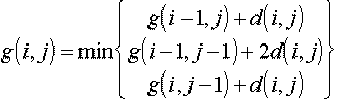
Finalement la distance entre les deux formes A et B sera:
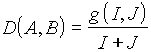
1 / (I+J) permet que D(A,B) soit indépendant des
longueurs de A et B.
Retour au début du
document
4.
Extensions sur les trois axes.
4.1. Reconnaissance
multilocuteur.
Une solution courante est de faire répéter tout le vocabulaire par une large
population de locuteur. Les répétitions de chaque mot du vocabulaire sont traitées par
un algorithme de classification (du type " nuées dynamiques " [ROG 87] par exemple) afin de déterminer des
classes de prononciation. La reconnaissance peut se faire par comparaison dynamique en utilisant
les centroïdes de ces classes, ou par un processus de décision comme " les k
plus proches voisins " [HAT 91].
4.2. Mots enchaînés.
Pour éliminer les pauses entre les mots, il faut pouvoir détecter les frontières qui
les séparent. De plus, il existera des différences de prononciation au début et à la
fin de chaque mot si le dictionnaire a été constitué de manière isolée.
Le second point peut être résolu en incluant lors de l’apprentissage une
référence " en contexte " pour chaque mot. Le premier point
nécessite une segmentation, à moins de considérer l’image acoustique de toute la
phrase comme étant la forme à identifier. C’est ce que permet une extension des
méthodes de comparaison dynamique [SIL 90],
la segmentation étant alors réalisée lors de la phase de reconnaissance.
4.3. Augmentation du
vocabulaire.
L’augmentation du vocabulaire entraîne la multiplication des références dans le
dictionnaire, donc des capacités de stockage et du nombre de calculs nécessaires. De
plus il apparaît le risque d’avoir des mots qui soient acoustiquement proches.
Les performances peuvent être améliorées en utilisant des connaissances phonétiques
[JUN 90] ou une grammaire qui permet
d’éviter les comparaisons grammaticalement impossibles. Par contre, cela ajoute des
contraintes syntaxiques qui diminuent la convivialité du dialogue et qui peuvent induire
des erreurs par un non-respect des règles de syntaxe.
4.4. Autres méthodes.
En fait, lorsqu’on cherche à étendre le système de RAP selon les axes
précédents, d’autres méthodes viennent en complément ou en concurrence de la comparaison dynamique, celle-ci
pouvant subsister dans l’étape de DAP: